
ChatGPT: Opening a New Era of economic and financial Research
Writing tweets: Xiaoyang Ren,Graduate of 2021, School of Finance, Zhongnan University of Economics and Law
Advisor:Yongbin Lv, Deputy Director of Innovation and Talent Base for Digital Technology and Finance
ChatGPT is scary good. We are not far from dangerously strong AI. --Elon Musk
Introduction
Online less than a Sunday live users broke a million, two months broke a hundred million...... At present, the AI intelligent chatbot ChatGPT has become popular all over the world and has become a phenomenon AI application. Whether you follow it or not, you can find it in the hot search of various news and video websites.
On ChatGPT's functions, Lei Qujiang, a professor at the School of Artificial Intelligence at the University of Chinese Academy of Sciences and executive chairman of the Asia-Pacific Society for Artificial Intelligence, said, "Using what it learns from a large corpus of texts, ChatGPT can self-generate text to help users find answers to questions."
In mid-March, OpenAI officially launched the latest version of GPT-4.0, which scored 128 points in the 2022 college entrance examination, equivalent to a person with the intelligence level of a college student. ChatGPT is now capable of communicating like a human by understanding and learning human language and interacting in the context of the chat. It can even complete tasks such as composing emails, video scripts, copywriting, translation, code, and writing papers.
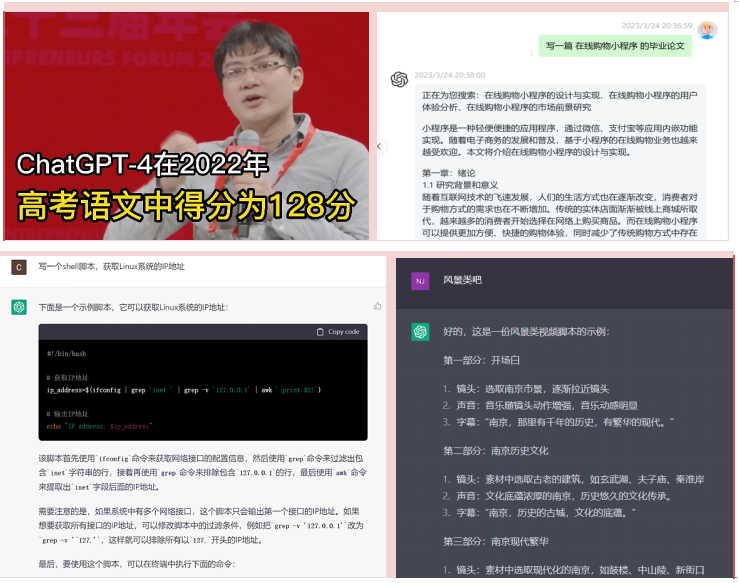
ChatGPT and the powerful content generation capability of the Large Language Model (LLM) behind it can replace human beings to undertake part of the daily academic work, which has attracted widespread attention in the industry. Researchers have used ChatGPT and other large language models to write papers, summarize literature, revise papers, and even be able to identify holes in studies and write computer code, including statistical analysis. More and more scholars pay attention to its function in the research field, but also to the rapid development of its scientific ethics, moral hazard has raised concerns.
From the perspective of economic and financial research, some scholars have made specific and in-depth discussions on the application of ChatGPT in related research fields. This tweet mainly refers to the following three literatures:
• NBER(2023):Language Models and Cognitive Automation for Economic Research
• FRL(2023):ChatGPT for (Finance) research: The Bananarama Conjecture
• Nature(2023):ChatGPT: Five Priorities for Research
ChatGPT's Popularity: Large Language Models(LLM)
A Large language model (LLM) is an artificial intelligence model capable of generating natural language text. Its main role is to automatically generate high-quality natural language content such as articles, dialogues, and translations. ChatGPT is a typical example of LLM.
Chip giant Nvidia introduces LLM application fields as follows:
In February 2023, Anton Korinek published a paper "Language Models and Cognitive Automation for Economic Research" in the NBER. An experimental discussion on how LLM and its cognitive automation may revolutionize the study of economics and other disciplines.
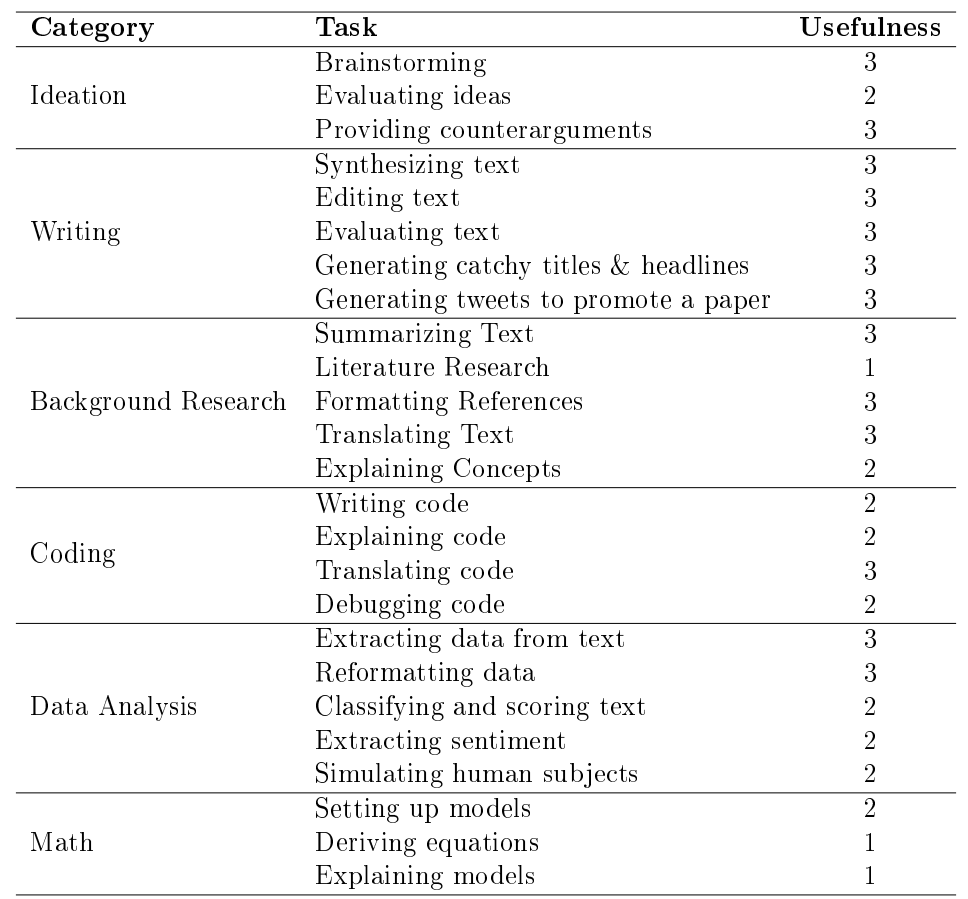
This paper describes use cases in six areas developed by LLM: conception, writing, background research, data analysis, coding, and mathematical derivation, and practices 25 use cases in each of these six areas. On this basis, each LLM capability is classified according to its specific practicality.
LLMS can help brainstorm, evaluate ideas and provide counterarguments during the ideation process, the paper notes. In writing, it can synthesize text, edit and evaluate text, generate catchy titles for papers, and generate promotional tweets. In background research, it can be used to generate abstracts, search and cite references, translate texts, interpret concepts and format references. In terms of coding, LLM can write code based on natural language instructions, interpret code, translate code, and even debug code is very powerful. For data analysis, LLMS can extract data from text, reformat data, classify text, extract emotion, and even generate data by simulating human objects. Finally, LLMS also began to show new abilities in mathematical derivation, from building models and completing derived equations to final model interpretation.
The following shows a specific use case from the paper -- the text synthesis function in the writing domain:

The paper presents the 25 example tasks described and finally classifies them in the form of a table according to the six application fields of LLM. In the third column of the table, the practicality of the LLM function is subjectively rated: 1 represents that the current function is only in the experimental stage, which is prone to produce inconsistent results and requires a lot of human supervision; 2 indicates that the function is practical and may save time, but it still needs careful supervision; 3 indicates that the function has very high practicability, and in most cases, it is integrated into the research workflow to further save time and improve efficiency.
In the short term, the authors conclude that cognitive automation through LLM will significantly improve the productivity of researchers, and it is expected that more and more researchers will incorporate LLM into their workflow. In the medium term, LLM-based will increasingly help generate more and more research paper content, while human researchers will focus on their comparative advantages, namely organizing research items, prompts, and evaluation-generated content; In the long run, with rapid advances in information technology and sufficient computation and iteration, sufficiently advanced AI systems may be able to generate and articulate superior economic models without relying on humans.
The cognitive automation brought about by the rapid rise of LLMS presents economists with important and urgent new research questions to ensure that the pursuit of increasingly advanced ultra-intelligent artificial systems is aligned with human goals.
ChatGPT helps finance research
It ain't what you do, it's the way that you do it And that's what gets results Song lyrics by Bananarama and Fun Boy Three (1982)
"It's not what you do, it's how you do it." Bananarama and Fun Boy Three (1982)
Debut of ChatGPT, an internationally renowned journal in Finance: On February 9, 2023, Michael Dowling and Brian Lucey published the paper "ChatGPT for (finance) research: "The Bananarama conjecture", an experimental analysis of the extent to which ChatGPT could help finance research.

The authors chose the field of cryptocurrencies and asked ChatGPT to perform four common tasks for scientific researchers:
1. Creative generation
2. Literature review
3. Data identification and preparation
4. Determination and implementation of test framework
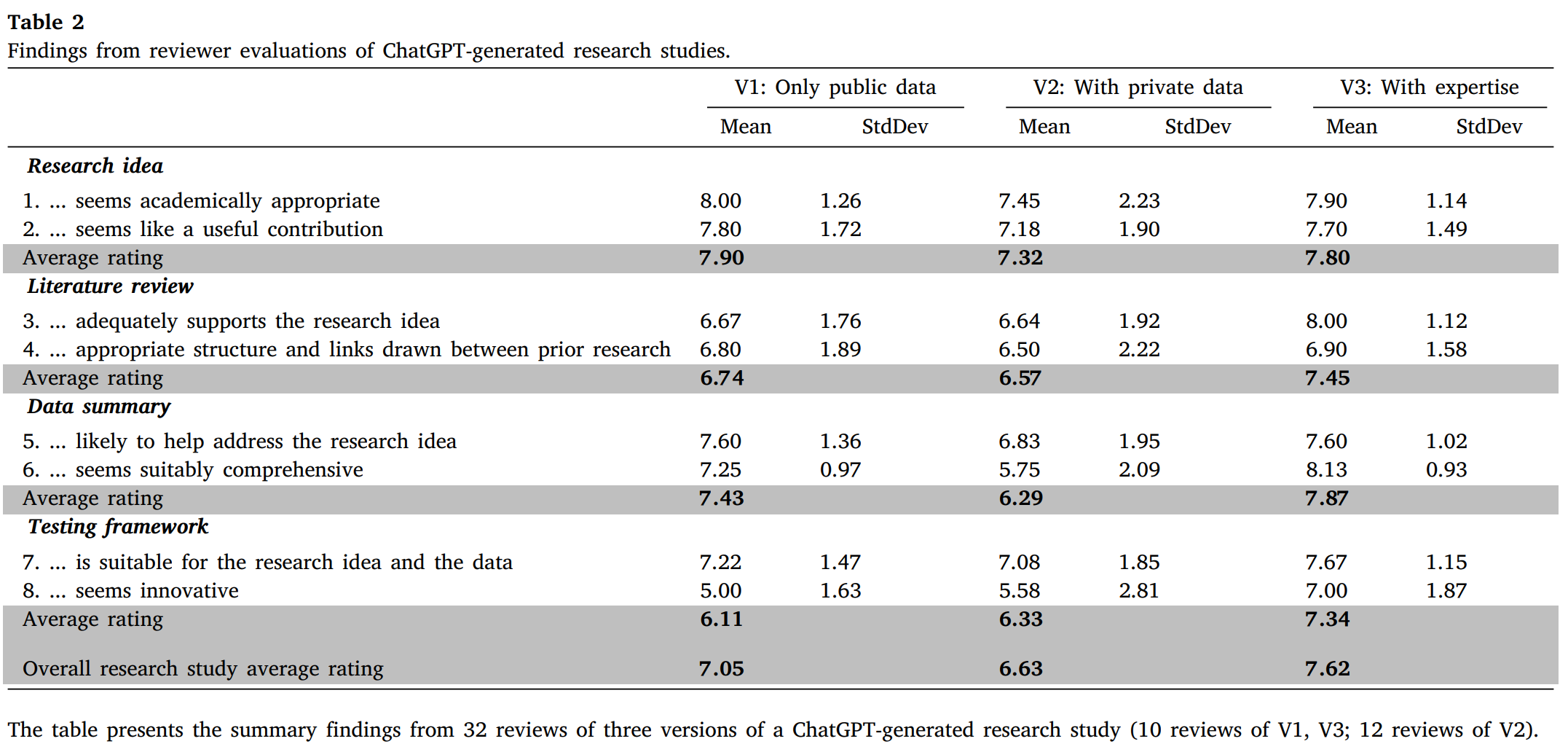
The paper examines three versions of the same cryptocurrency research idea, each of which includes the four research phases above. The first version (V1: Public data only) uses only the public data already available in ChatGPT. The second version (V2: Adding private data) combines private data to assist in generating the study phase. The third version (V3: Private Data and Expertise) further combines the expertise of the researcher's domain with private data.

The paper gives the outline generated by ChatGPT to essay reviewers in the field to score how likely it is to be accepted. The reviewers are asked to evaluate the output of each stage in two aspects. The evaluation criteria are shown in the figure. The final results consist of a rating between 1 (highly disagree) and 10 (highly agree) based on the specified criteria, assessing the likelihood of these outputs being acceptable to journals with a minimum ABS2 star.
主要研究成果为:
1. 检查各个研究阶段,发现最高的评分为第一阶段--创意生成,这是在于ChatGPT可以访问数十亿参数和文本,特别擅长对现有思想的广泛探索。
2. 数据汇总阶段也十分强大,或许是因为这一阶段往往是研究中易于识别的文本“块”中的不同部分。
3. 文献综述与测试框架的表现并不成功。文献综述是将研究思路与方法论联系起来的内在工具,测试框架将研究思路、文献综述和数据汇总三个方面联系起来。该模型似乎不太能够将多个内部产生的想法联系起来。
4. 添加了私有数据的版本表现不佳,似乎是由于模型过度依赖所提供的私有数据,并限制了对其他有益的公共数据的访问。
5. V3研究的结果表现卓越,因为研究人员可以观察到任何缺失的环节,并要求平台进一步迭代以解决这些空白。
上述实验抛出了一个值得思考的问题:拥有ChatGPT如此高水平的指导和帮助,研究人员会声称自己的研究成果正确吗?如何对待生成作品?Iaia(2022)指出,根据欧盟法律,在“充分”的人类监督下,人工智能生成的工作通常被认为属于人类创造者。
当然,“充分”这一定义仍然相当模糊。这表明,使用私人数据和更高水平迭代的研究可以被认为是研究人员自己的工作,但可能不是只使用公共数据和简单问题提示的基础研究研究。正如Bananarama歌词中所提到的:“关键不在于你做了什么,而在于你做事的方式,这才是(道德上可以接受的)结果。”
ChatGPT:热话题需要冷思考
与上述两篇论文最后的担忧一致,许多学者都认可ChatGPT这类模型在帮助顺利进行研究工作、缩短出版时间的巨大助力,但另一方面也担心它可能降低研究的质量和透明度,从而产生道德问题。现如今ChatGPT爆火,研究界的当务之急是需冷静下来思考并讨论这项潜在的颠覆性技术可能带来的严重影响。
2023年2月3日,荷兰阿姆斯特丹大学的多位教授在Nature杂志发表文章“ChatGPT: five priorities for research”,讨论了科学界应当如何应对ChatGPT。

The paper Outlines five key issues:
1. Insist on manual verification
Using conversational AI for dedicated research is likely to introduce problems of inaccuracy, bias and plagiarism. These errors may have been caused by ChatGPT's failure to extract relevant information during training, or its inability to distinguish between sources of credibility. Researchers need to be vigilant, and expert-driven fact-checking and verification processes will be essential.
2. Set rules of accountability
In a research paper, the author's contribution statement and acknowledgments should clearly and specifically state whether and to what extent AI technologies such as ChatGPT were used in manuscript preparation and analysis. They should also indicate which LLMs are used. This will alert editors and reviewers to scrutinize manuscripts more closely for potential bias, inaccuracies, and improper sources. "Authorship implies responsibility for the work, which cannot be effectively applied to the LLMs. Authors who use LLMs in any way while writing a paper should document their use in the methods or acknowledgements section, if appropriate." Magdalena Skipper, editor-in-chief of Nature
3. Invest in truly open large language models
The near-monopolies a handful of tech companies now have in search, word processing and access to information raise considerable ethical concerns. One of the most pressing concerns in the research community is the lack of transparency. ChatGPT includes the basic training set of its predecessor as well as the LLMs are not public, and tech companies may conceal their inner workings. This goes against the trend towards transparency and openness in science, and makes it hard to spot sources or gaps in chatbot knowledge. To combat this opacity, priority should be given to the development and implementation of open source AI technologies.
4. Embrace the benefits of artificial intelligence
As noted in the study, ChatGPT allows researchers to publish their results faster, giving them more time to focus on new experimental designs and significantly accelerating innovation. Ai technology could rebalance the academic skill set. In the future, AI chatbots may generate hypotheses, formulate methods, create experiments, analyze and interpret data, and write manuscripts. People's creativity and originality, education, training and productive interaction with others may remain the key to conducting relevant and innovative research.
5. Broaden the scope of discussion
Given the disruptive potential of LLMS, the research community needs to organise an urgent and wide-ranging discussion. First, it is recommended that each research group convene a meeting immediately to discuss and try ChatGPT themselves. Second, immediately organize an ongoing international forum on the development and responsible use of LLMS for research. Stakeholders, including scientists from different disciplines, technology companies, large research funders, academies, publishers, ngos, and privacy and legal experts will participate in the forum.
List of issues that can be discussed at the forum:

conclusion
"ChatGPT is very powerful and daunting. We are not far away from a dangerously strong AI." Elon Musk, one of OpenAI's founders, tweeted about his ChatGPT late last year.
All in all, as a phenomenal technology product, ChatGPT's performance in the field of artificial intelligence-generated content is undoubtedly revolutionary, with profound implications for science and society. It is not hard to predict that as deep learning algorithms evolve, ChatGPT will become more accurate and serve a wider range of services, changing the fundamental approach to financial and economic research.
In an age of rapid information technology, the use of ChatGPT and the technology behind it has become unavoidable, and banning it would be counterproductive. What is more important now is to embrace the opportunities and manage the risks that this kind of AI presents, and to believe that the scientific community will eventually find a way to benefit from conversational AI without losing the natural human qualities of curiosity, imagination, and exploration that make research possible.
Description: The tweets come from cutting-edge literature recommended by researchers in the base, and are sorted out by students on the basis of original text extraction and group discussion. Tweets are for study only, not for other purposes!